通过 Node.js 实现一个简单爬虫,爬取豆瓣热门电影。主要会用到的模块(包)有:http,fs,path,cheerio。
这里用一个跑在本地的 http server 来模拟在线爬豆瓣网。
douban-server.tar.gz 是由实验楼提供的在本地模拟豆瓣网的程序。具体的代码实现参考 git:ipoplar ,其中 growth.md 是遇到的问题。
Operation
解压 douban-server.tar.gz1
tar zxvf douban-server.tar.gz
进入解压后的目录,启动服务:
1 | npm start |
创建文件夹 spider, 进入文件夹,输入 npm init , 初始化项目,会得到类似与小编的文件。(在初始化项目要添加第三方包 npm install cheerio --save)
运行 node spider.js 会抓取到想要的信息(将抓取到的图片放到 img 文件夹下,将电影信息放置在 data/data.json 中)
Problems and growth
在小编现在的 spider.js 中的爬虫url信息如下图所示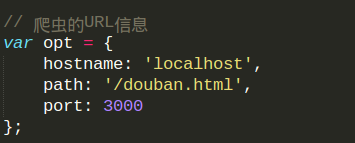
当改为某个在线的网址,在此以妙味课堂的网址为例了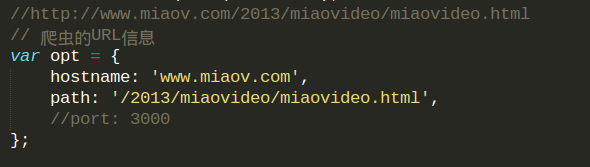
那么在这里要要注意什么呢?
1.hostname ,注意这两出的都没有 ‘http://‘ 部分,那么如果加了会怎么样呢?看下图喽:
2.port , 当抓取在线的网站的信息时,要记着去掉 port:3000, 不然又会有错:
3 要注意 host 和 path 的写法。对比前两幅图即可得。
res.setEncoding();
用于使流(Stream)返回指定编码的字符串,具体可以看Node.js的api文档:Stream,Node.js不支持GBK编码,如果需要处理GBK编码的页面,可以使用 iconv-lite 这个包。一般对文件设置为binary,对字符串设置为utf-8。
参考的地址: https://cnodejs.org/topic/5203a71844e76d216a727d2e